werkzeug源码分析(local.py)
有人说flask的上下文机制是整个框架的精华部分,有人说它神奇的g让人费解。werkzeug的local.py就是它的具体实现。这个看似神奇的机制背后加上应用代码也不过两三百行。不过好像坑还是比较深的。另外flask的0.1版本才200多行代码。值得瞅一下
直观感受上下文
使用wrk进行压测wrk -t300 -c300 -d10s http://127.0.0.1:5000
1 | import time |
为什么会有Local
比较抽象的解释叫它线程内共享变量,下面来个例子
1 | import threading |
可以看出就是一全局对象对它设置的属性在线程间是隔离的。可是这又有什么用。我们作为框架使用者逻辑一般都是写在一起的,没有人会故意去像这样写
1 | l = threading.local() |
可是我们使用的是框架!线程的调起不是我们主动去操作的。框架会有一些第三方扩展。它们依靠此机制给我们提供接口,比如来个官方示例
1 | import sqlite3 |
Local的实现原理很简单,这里不详述了。就是前一篇博文说的字典的dict[key] = value是线程安全的。其实threading.local也是一样的作用,那么为什么不用它。
- 支持了greenlet(本博文只会涉及到多线程情况)
- 自带的写法太特么恶心了,那个源码我都快看吐了,不如自己写一个(我都没看透自带的为什么要那么写,如果你能轻松看明白,那么你肯定是看魔术方法的大神)
简述下自带的逻辑,主要是这几句
1 | # python2.7.11代码 |
在同一线程内threading.current_thread()是同一对象,有一个_patch函数,该函数在local属性被调用前提前调用,将current_thread().__dict__相关的内容绑定在local.__dict__上。
为什么会有LocalStack
它主要将上面的Local由l.key = value变成了l.push(value)。变成了栈结构。可是从上面的直观感受上下文部分可以看到在多线程环境下任一时刻栈里面都仅有一个内容。那么还为什么要使用栈呢,往下看。
为什么会有LocalProxy
从名字就可以看出来是代理模式。可以看看github上的设计模式,同样是讲的代理模式,flask的实际应用就比这个例子要高明的多
我们使用代理是为了绕过防火墙访问外面的世界,那么LocalProxy这个代理是干啥子的呢。设想一下。我们使用了l = Local()并且在上面给一个属性赋值了l.key = value。那么当你要调用的时候就使用l.key就好啦。现在我们没有直接用Local用的是l = LocalStack(),l.push(RequestContext()),request这个属性又在
RequestContext()这个对象上。那么我们要访问request怎么办!此时你就要执行l.top.request进行访问。可是优雅呢!优雅呢!优雅呢!优雅哪里去了。我们很懒,我们想执行一个request就能代替l.top.request(有人会问为什么不直接写死reques = l.top.request,那是因为它是死!!!的,而l.top.request是随着线程进入退出一直出入栈动态变化的,我们只能在每次使用的时候执行l.top.request得到正确的结果)。→_→这就是这个代理能为我们做的
执行repr(current_app)的调用图,请无视pycall那一块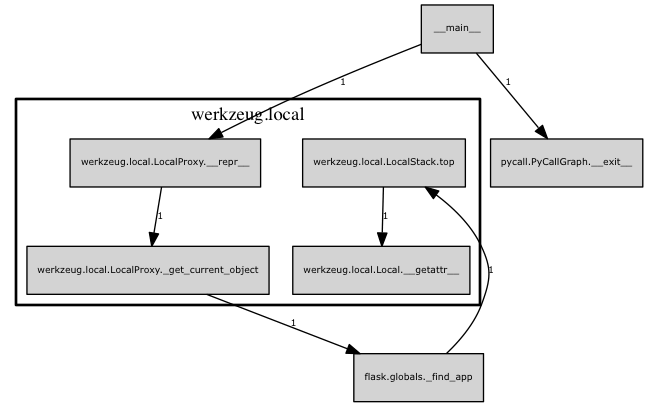
1 | def _find_app(): |
在LocalProxy里面我们写了一个回调函数,当对LocalProxy属性进行访问的时候,它永远都是先执行_get_current_object,该函数就是执行我们写入的回调函数得到访问对象,比如current_app就是得到_app_ctx_stack.top.app对象。最后再对得到的对象进行属性访问
对LocalProxy讲3个小细节
_init_中有
object.__setattr__(self, '_LocalProxy__local', local)。如果你要确保对一个对象的__dict__中加入内容,需要使用object.__setattr__,使用self.x、setattr(self,’x’)、self.__dict\[x]都是不确定的,因为它self这个对象可能会重写自身的_setattr_,其次对于私有变量。执行__setattr__的时候需要变换1
2
3
4
5class Foo():
def __init__(self):
self.__a = 1
print(Foo().__dict__)
# {'_Foo__a': 1}最下面同时也对所有可列举的魔术方法进行了代理
__str__ = lambda x: str(x._get_current_object())由于代理的存在原始对象的访问需要通过_get_current_object(其实对于看过代码的这应该是废话O_o)
1
2
3
4
5
6
7from flask import Flask,current_app
from flask.globals import _app_ctx_stack
with Flask(__name__).app_context():
print(current_app is _app_ctx_stack.top.app)
print(current_app._get_current_object() is _app_ctx_stack.top.app)
# False
# True
request、session和g
这几个和上下文息息相关,比如离开了对应的上下文它们完全无法使用
1 | from flask import request, session, g |
flask的0.1版本是只有RequestContext请求上下文,没有应用上下文的。直到0.9版本才用二三十行代码加上AppContext应用上下文
为什么要加上应用上下文呢。官方文档我没有找到很详尽的解释,只有一段简要的描述,同时参考了下别人的博客。我个人理解是为了处理单独使用应用上下文不使用请求上下文的情况。另外文档有creating such a request context is an unnecessarily expensive operation在某些情况使用请求上下文是昂贵的没有必要的操作。参考下面的代码
1 | from flask import Flask,current_app |
首先可以看到执行app_context()的时候有了应用上下文,和请求上下文一毛钱关系都没有。看下代码就是return AppContext(self),它自己有个__enter__函数执行了push。这有什么用呢。比如你要在命令行调用下你写的数据库函数。很明显它需要数据库的配置app.config。如果没有应用上下文,那么你需要先创建请求上下文。现在你只需要创建应用上下文了(比请求上下文更轻量)。再者当我们一次性进入了多个应用上下文的时候此时栈里面就不止一个元素了。所以。。。。这也是上面问的为什么要用栈
第二个例子只有当请求发送后应用上下文和请求上下文才会同时入栈。且同时出栈,所以网上有博客写一个应用上下文会包含多个请求上下文这是不对的。并且绝对不能理解为应用上下文的生存周期是一个app从启动到关闭这个过程

 官方网站:
官方网站: